Academic Publication: Humanities and Social Sciences Communications (Nature Portfolio, 2025)
Open-Source Repository: https://github.com/UKGANG/tobit
This project spans a complete cycle of scientific inquiry—from statistical modeling, to publication in a Nature Portfolio sub-journal, to releasing a production-grade Python library to the open-source community. Funded by the U.S. Office of Research Integrity (Project Grants: ORIIR190049 and ORIIR180041), the work models and predicts the failure lifecycles of digital resources shared in scientific literature (e.g., databases, code repositories, and online tools).
Optimized Mathematical Modeling & Algorithm Design
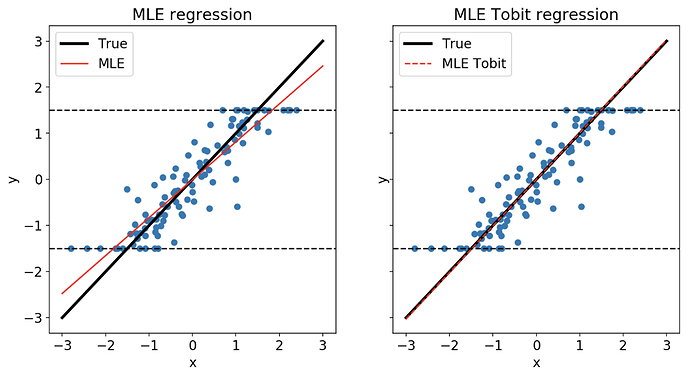
True survival times of shared resources in scientific literature are strongly censored—bounded on the right by the observation window and on the left by immediate post-publication initialization failures. Ordinary linear regression or off-the-shelf MLOps models cannot capture this structure. We designed and implemented a Tobit censored regression model with an Elastic Net regularization penalty.
1. Latent Variable Formulation
Assume the underlying uncensored resource lifetime $y_i^*$ follows:
$$y_i^* = x_i \beta + \epsilon_i, \quad \epsilon_i \sim \mathcal{N}(0, \sigma^2)$$The observed lifetime $y_i$ is subject to censoring:
$$y_i = \begin{cases} y_L & \text{if } y_i^* \le y_L \\ y_i^* & \text{if } y_L < y_i^* < y_R \\ y_R & \text{if } y_i^* \ge y_R \end{cases}$$Censoring mechanism: When latent values fall outside the observation interval $[y_L, y_R]$, exact values are unobservable—producing pulse-like probability mass at both bounds.
2. Maximum A Posteriori (MAP) Estimation
To prevent overfitting on high-dimensional scholarly features (URL validation status, publisher metadata, author citation metrics, etc.), we use a penalized likelihood with Elastic Net regularization (L1 + L2)—equivalent to MAP estimation under combined Laplace and Gaussian priors:
$$\begin{aligned} \mathcal{L}_{\text{MAP}}(\beta, \sigma) &= -\sum_{i \in \text{Left}} \ln \Phi\left(\frac{y_L - x_i \beta}{\sigma}\right) \\ &\quad - \sum_{i \in \text{Mid}} \left[ \ln \phi\left(\frac{y_i - x_i \beta}{\sigma}\right) - \ln \sigma \right] \\ &\quad - \sum_{i \in \text{Right}} \ln \Phi\left(\frac{x_i \beta - y_R}{\sigma}\right) \\ &\quad + \lambda \left( \alpha \|\beta\|_1 + (1-\alpha) \frac{1}{2} \|\beta\|_2^2 \right) \end{aligned}$$Here $\Phi$ and $\phi$ denote the CDF and PDF of the standard normal distribution, and $\beta$ is the coefficient vector.
3. Analytical Gradient Acceleration (Jacobian)
Standard optimizers that rely on numerical finite-difference gradients are inefficient and numerically unstable at ten-million-scale sample sizes. We advanced and implemented exact analytical gradients for the loss function (_tobit_neg_log_likelihood_der), using the inverse Mills ratio $\lambda(z_i) = \frac{\phi(z_i)}{\Phi(z_i)}$ for all three observation types:
- For left-censored points: $\frac{\partial \mathcal{L}}{\partial \beta} = \frac{x_i}{\sigma} \lambda\left(\frac{y_L - x_i \beta}{\sigma}\right)$
- For right-censored points: $\frac{\partial \mathcal{L}}{\partial \beta} = -\frac{x_i}{\sigma} \lambda\left(\frac{x_i \beta - y_R}{\sigma}\right)$
- For uncensored (mid-interval) points: closed-form Gaussian density gradients
- This analytical gradient lets optimizers such as
L-BFGS-Bconverge in far fewer iterations, enabling efficient processing of massive datasets.
Production-Grade Open-Source Library: Tobit-EN
To make the research reproducible for industry use, I packaged and released the implementation on PyPI.
- scikit-learn compatibility: The
TobitRegressorclass inherits fromBaseEstimatorandRegressorMixin, dropping into standardGridSearchCVworkflows and ML pipelines without glue code. - Bootstrapping: Built-in bootstrap resampling extracts rank-stable core feature contributions under highly collinear data.