我的工作横跨 模型与算法设计、大规模训练 与 生产级部署——从自定义架构与截断回归研究,到 GPU/TPU 分布式训练与企业级推理落地。
具体包括:面向科学文献与元数据的截断回归与开源研究工具;面向形态学等高吞吐场景的大规模视觉训练与低延迟推理;基于创新算法的企业计算平台异常检测;以及面向高吞吐运行时负载的分支强化学习序贯决策。
我的工作横跨 模型与算法设计、大规模训练 与 生产级部署——从自定义架构与截断回归研究,到 GPU/TPU 分布式训练与企业级推理落地。
具体包括:面向科学文献与元数据的截断回归与开源研究工具;面向形态学等高吞吐场景的大规模视觉训练与低延迟推理;基于创新算法的企业计算平台异常检测;以及面向高吞吐运行时负载的分支强化学习序贯决策。

设计并开发了一套高吞吐序贯决策引擎,面向云计算决策平台,在极端、高频的运行时负载下提供资源供给与调度相关的实时序贯决策。该 Stealth Pilot 自 2023 年 6 月持续至今,在系统规模上落地深度强化学习——贯通算法设计、分布式 GPU 训练与性能约束下的策略对齐。 核心技术栈: PyTorch · 分支对决 Q 网络(BDQ)· HF Accelerate · DeepSpeed · Ray Job/Serve · DDP · 偏好对齐(Preference Alignment) 系统概览与序贯决策闭环 引擎将平台上的供给与调度问题建模为马尔可夫决策过程(MDP):Macro 信息编码器与 Micro 信息编码器并行处理多源平台观测(前者聚合平台级宏观信号,后者捕捉局部高频观测),融合后馈入 Actor-Critic 主策略;主头输出离散控制动作,并行的 Preference Alignment 辅助网络在共享策略表示上施加安全与偏好约束。决策在毫秒级间隔内完成,并平衡吞吐量、尾延迟与资源利用率。 [图 1: 高频 DRL 决策闭环] 平台观测 Observability Macro 编码 并行 Micro 编码 并行 BDQ 策略 Actor-Critic 共享表示 控制动作 主头 偏好对齐 辅助网络 GPU Replay Buffer 决策闭环: 平台观测并行经 Macro / Micro 信息编码器融合后输入 BDQ 主策略;主头输出控制动作,Preference Alignment 辅助网络并行挂载于共享表示;二者产生的转移写入 GPU 驻留 replay buffer,供分布式离策略更新使用。 ...
担任 NetApp 核心 AI & ML 研发团队关键成员期间,共同设计并申请了多项核心技术专利,这些专利构成了 NetApp ONTAP 实时勒索软件自主防护(Autonomous Ransomware Protection, ARP)引擎的算法基石。该方案将前沿的深度学习和语义分析技术引入到实时的存储安全中,并使其能在极其严苛的企业级延迟和算力预算下稳定运行。 核心技术架构与专利矩阵 ARP 防护引擎包含三个相互协作的高级检测监控层: 1. 恶意加密检测(基于字节频率分布与机器学习) 相关专利:Malicious encryption detection based on byte frequency distribution(美国专利公开号:US20250298892A1) 技术原理:传统的勒索软件检测多依赖于信息熵,在面对局部加密或原本低熵的文件块时极易失效,且极易将勒索恶意加密与合法的系统加密(如压缩包、PGP 密钥)相混淆。我们通过锁定修改后的数据块(如 VMDK 虚拟盘快照增量),提取其 256 维的字节频率分布(BFD)特征向量,输入我们专门训练并深度优化的高吞吐量神经网络分类器,在数据块落盘的极短时间内实现精准判定。 [图 1: 字节频率分布 (BFD) 特征曲线示意图] 字节出现频率 字节取值 (0 - 255) 合法压缩/加密 (平缓分布) 勒索加密异常特征尖峰 虚线: 合法压缩或加密文件块的字节频率分布(近似均匀分布)。红线: 勒索软件恶意加密所特有的非均匀字节波形尖峰。 ...
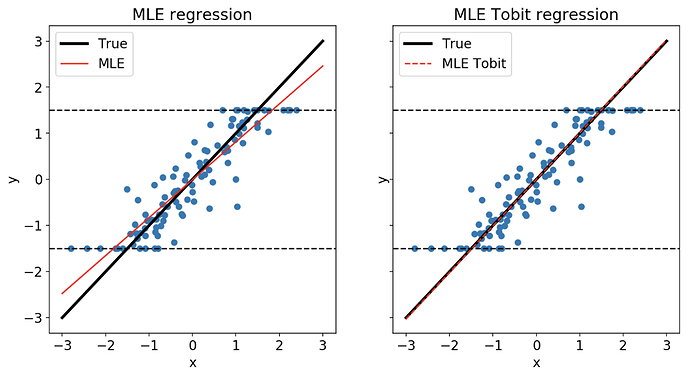
学术发表:Humanities and Social Sciences Communications (Nature Portfolio, 2025) 开源仓库:https://github.com/UKGANG/tobit 本项目展示了一个完整的科学探索生命周期——从提出数理统计模型,到在 Nature 旗下子刊发表学术论文,再到向开源社区贡献工业级 Python 计算包。该研究由 美国联邦研究诚信办公室(Office of Research Integrity,项目资助编号:ORIIR190049 与 ORIIR180041) 资据,专门用于建模和预测科学文献中分享的数字资源(如数据库、代码仓库、在线工具等)的失效生命周期。 优化数学建模与算法求解 由于科学文献中共享资源的真实生存时间在统计学上存在明显的截断特征(在右侧受限于观测窗口的截止点,在左侧受限于论文刚发表即失效的初始化失败),普通的线性回归或 MLOps 模型无法有效建模。我们为此设计并实现了一个带 Elastic Net 正则化惩罚项的 Tobit 截断回归模型。 1. 潜在变量公式表达 假定底层未截断的资源寿命 $y_i^*$ 服从: $$y_i^* = x_i \beta + \epsilon_i, \quad \epsilon_i \sim \mathcal{N}(0, \sigma^2)$$而我们实际观测到的寿命 $y_i$ 则服从如下截断约束: $$y_i = \begin{cases} y_L & \text{if } y_i^* \le y_L \\ y_i^* & \text{if } y_L < y_i^* < y_R \\ y_R & \text{if } y_i^* \ge y_R \end{cases}$$ [图 1: Tobit 截断模型概率密度函数 (PDF)] 左截断界限 y_L (立即失效) 右截断界限 y_R (窗口限制) y_L y_R 截断分布机制: 当潜在分布超越观测区间边界 $[y_L, y_R]$ 时,无法观测到确切值,从而在边界上限 $y_R$ 和下限 $y_L$ 处产生概率密度的脉冲式累积。 ...

在 Deepcell 期间,负责设计、开发并扩展一套超高性能的细胞图像分类与智能筛选平台。该平台允许生物学家与药物学者依托细胞表面粗糙形态学特征在极短的时间内对细胞群落进行分析、分类并进行物理筛选归类,在实验室硬件仪器和云端深度学习集群之间搭建起了高效运转的桥梁。 核心工程优化与算力加速 我们在平台建设中的核心研发方向是最大化模型吞吐量、极力压低云端算力开销、并建立极其稳健的超低延迟推理通道。 1. 超高吞吐量实时流处理通道 为了处理由实验室硬件设备实时采集产生的细胞图像数据流,我们建立了一条高度硬件加速的并行流式推理流水线,贯穿采集、量化推理、服务化分发至终端二维可视化: [图 1: 实时 AI 推理加速管道流程图] Triton 推理服务 在线热路径 TensorRT INT8 · 动态批处理 · GPU 队列 离线编译 ONNX → TensorRT INT8 · PTQ 校准 显微硬件 数据队列 并行预处理 PyTorch 模型 Embeddings UMAP 终端 管道加速逻辑(示意): 实时热路径为:光学硬件 → 数据队列 → 并行 CV 预处理,自左侧进入 Triton 在线层,由 TensorRT INT8 引擎输出嵌入向量,再经 UMAP 终端展示。训练得到的 PyTorch 模型亦自左侧注入离线编译层,在发布阶段完成 ONNX → TensorRT INT8(PTQ 校准),产物供在线层加载 serving,不在热路径重复执行。 ...
本项目与短租数据公司 AirDNA 合作,围绕 Airbnb 平台用户评论文本,采用统计与机器学习方法,对共享经济短租市场的供需关系及其宏观影响进行建模分析,并刻画不同用户群的行为特征。 基于结构方程模型分析短租供需关系 本项目在文本侧基于自然语言处理 (NLP) 与预训练 BERT,量化用户偏好及对房东的信任程度;在结构建模侧综合运用结构方程模型 (SEM)、主成分分析 (PCA)、探索性/验证性因子分析 (EFA/CFA)、广义线性回归与潜在狄利克雷分配 (LDA) 等方法,为疫情后房东应对市场不确定性提供决策依据。相关分析结论已支撑 AirDNA 向短租行业输出高价值数据与洞察。

作为团队负责人,我主导了面向生物科技专利文献的知识图谱研发:明确研究方向、对齐交付里程碑,并把控数据流水线与图谱架构设计。项目的核心目标是将非结构化专利文本转化为结构化的基因序列记录,以支撑下游的 IP 分析与交互式探索。 结合词性标注与领域规则,从专利文档中定位含序列信息的段落 团队构建了自动化 ETL 流水线,从专利文档中抽取基因名称、DNA/蛋白质序列及分类学提及;抽取结果集成至统一的图谱模式中,并接入 BLAST+ 数据库进行分类群校验,从而过滤因 OCR 识别误差或生物命名不一致带来的噪声。 在文本挖掘方面,方案结合了词性标注(POS tagging)与领域特定规则,以定位权利要求书和说明书中包含序列信息的段落——相比普通的生物医学摘要,这种定制规则能更好应对复杂、半结构化的生物专利法律文本。 为便利检索与探索,项目实现了一个内部检索系统,支持对已抽取的序列与关联实体发起查询,并在图谱中召回匹配或相似的图节点。该结构化检索系统可作为传统关键词搜索的重要补充,加速现有技术(prior art)检索与序列重叠分析等工作流。 该项目端到端验证了流水线的可行性,为生命科学专利 IP 分析的后续产品决策奠定了基础。
GitHub: sciosci/ImageAnnotatorJS
ImageAnnotatorJS 是一个模块化 JavaScript 库(AMD 标准),面向前端工程师构建网页端图像标注与审查系统。用户可在 HTML5 Canvas 上绘制并管理各类矢量标注形状,支撑学术图像检验、分析与研究数据采集。该项目部分开发经费来自美国卫生与公众服务部(HHS)下属研究诚信办公室(ORI),资助编号 ORIIIR190049 与 ORIIR180041。
...仪表盘 标注弹窗 标注系统界面截图 SOS+CD 实验室 图像分析应用面向科研及其他业务场景,提供了一个简便易用的 Web 界面与服务。用户可从 PDF 导入图像,完成分析、存储与标注;后端另有多套 API,支撑更深入的图像处理与分析。 应用基于机器学习算法,在识别与标注任务上保持较高精度,便于研究人员高效处理大规模图像数据。界面设计强调直观与高效;结合灵活的分析能力与可扩展 API,SOS+CD 实验室 的这一工具适用于各类图像数据相关的研发工作。
该问答机器人项目涉及开发自然语言处理 (NLP) 模型,向公众提供有关 COVID-19 的最新动态。担任团队负责人期间,负责主持每周的 POC 演示、指导团队分解任务、跟踪项目进度并监督代码实现。 为了构建该应用,我们首先需要收集数据。我们构建了一个网络爬虫,用于从 Quora 社区收集问句数据,接着使用预训练模型 BERT 进行迁移学习,在爬取的语料集上训练我们的 NLP 模型。在研究了用于该 NLP 任务的几种损失函数后,我们决定使用余弦相似度,并结合 ETL 流程与基于 KNN 算法的相似度比对逻辑来实现。 为了让用户能方便地使用问答机器人,我们使用 Python Dash App 框架创建了一个 Web 门户网站。该应用不仅为公众提供疫情相关信息,同时收集用户提出的问题以用于社会科学研究。为了优化模型性能,我们尝试了多种方法,如微调 BERT 的超参数、优化序列长度和采用不同的批次大小。最终产品是一个能够向用户提供最新 COVID-19 资讯并收集学术研究问句的智能问答机器人。
该实验旨在通过针对 X 射线影像的数据增强,提高 AI 模型的鲁棒性。担任项目负责人期间,负责设计生成对抗网络 (GAN) 的架构、规划实验步骤以及分析模型性能。 生成对抗网络系统 生成图像质量演进过程 首先尝试了两种不同的网络架构,通过广泛的超参数微调来优化 GAN 性能。此外,为捕获 X 射线图像的特征,通过附加 Sobel 滤波器对网络进行了改进。最后,采用非参数假设检验 (NHST) 分析网络性能,证实了该方法的有效性。 考虑到 Google Colab 上 GPU 显存及运行时间的限制,使用 TensorFlow 检查点 (checkpoint) 功能对程序进行了增强,以支持可中断、断点续传的训练过程。这使得优化后的网络能够生成逼真的合成 X 射线图像,作为医学研究中数据增强的样本。总体而言,该项目展示了在增强 X 射线筛查图像以提高 AI 模型性能方面的有效方法。

该 POC 项目专为华能山西秦岭发电厂开发,用于预测发电量输出。担任首席架构师期间,负责监督该应用的整体设计开发;在与发电厂工程总监紧密合作的基础上,团队深入理解业务需求,确保应用设计能够精准满足其需要。 该应用在前端集成了 REST 服务,允许用户查询并以图形化直观展示预测的发电量。项目使用微信小程序平台作为前端,使用户能够通过移动设备轻松访问该应用。为了确保应用的鲁棒性与可靠性,开发团队在整个开发过程中进行了全面的测试与验证。 总体而言,该 POC 项目成功证明了利用机器学习预测发电量输出的可行性。该小程序提供了精准的预测和友好的用户界面,得到了电厂工程团队的高度评价。基于该项目的成功,未来还将探索将该应用进一步推广部署到其他发电厂的机会。

该电商项目将商户 API 无缝集成至平台,为其他应用提供报价与下单服务。担任高级 Java 工程师期间,负责开发新功能以满足业务团队需求,并支撑项目的快速增长。 为改善用户体验,重新设计了 API,使支付服务更加便捷;并带领两人小组实现追踪日志(tracking log)模块,大幅简化了故障排查流程。此外,团队还引入了一套子系统,供业务分析团队开展 A/B 测试。 针对第三方服务回传背压(backpressure)信号的问题,提出并实现了令牌桶(token bucket)限流算法;为进一步优化系统性能,将 MongoDB Streaming 与函数式编程相结合,将系统吞吐量提升至 300 TPS。 项目还首次在生产环境中落地统计分析能力,进一步提升了系统整体性能;上述工作对该快速演进项目的成功起到了关键作用。
该项目通过为其他企业级应用提供统一的文件存储和邮件发送服务,成为了公司系统的底层骨干。担任资深 Java 软件工程师期间,在候选技术选型、架构设计、核心代码编写以及指导初级同事等方面发挥了核心作用。 在重构整个系统之前,旧有的遗留系统陈旧且难以维护,迫使其他应用必须适应其局限性。期间识别并解决了一系列系统瓶颈,例如直接的 MQ 消息队列同步调用,以及 NFS 网络文件系统空间中存储的大量无用过期数据。 为精简和优化系统,第一阶段将 Twilio 短信发送服务和 Sparkpost API 进行了集中化封装,同时设计了定期清理计划以清除过期文件。在架构设计上,引入职责链模式(Chain of Responsibility)重新组织代码,并通过消息队列(JMS)和监控接口来分析内存快照及排查故障。 经过这些重构努力,系统的请求处理速度提升了三倍,其他项目组的反馈也表明新 API 的易用性大大增强;相关改进使技术平台能够更好地跟上最新业务发展的需要。
新加坡安微尼亚山医院 该项目专为新加坡安微尼亚山医院(Mount Alvernia Hospital)开发,提供符合患者期望的患者入院登记与医疗信息管理服务。 担任资深 Java 软件工程师期间,负责指导初级团队成员、进行代码审查以及监督项目开发;并基于 Wacom 签批板平台开发电子签名模块,通过电磁笔捕捉患者手写签名轨迹,将其转化为 Base64 编码字符串用于 HTML5 页面可视化。 为进一步优化系统性能,引入了后端缓存机制以加速页面中签名的加载速度,进一步提升了用户体验;相关改进对项目成功落地起到了关键作用,保障了医院高效提供患者护理与医疗管理服务。
SATA 社区健康医疗中心 该系统为新加坡 SATA 社区健康综合医疗中心开发,提供患者信息整理、住院流程管理、药品仓储管理、分支机构收入报表生成以及市民补助扣除计算等服务。 担任资深 Java 软件工程师期间,职责包括使用 EJB 2、Struts1 和 iBATIS 开发系统扩展功能;核心贡献之一是利用 Oracle 中的聚集索引(clustered indexing)优化数据库分页查询功能。 该项优化显著提高了系统响应性能,为医护人员及患者带来了更佳的使用体验,也为系统稳定运转及中心高质量医疗服务提供了重要支撑。

该应用作为全球代理机构提交公司注册请求的统一平台。 担任项目开发人员期间,负责扩展功能开发,并评估浏览器兼容性改造任务;主要使用 Java,通过分析代码库扫描 JSP 与 JavaScript 文件,定位存在问题的代码片段。 上述分析帮助团队更准确地评估任务范围与风险等级,最终保障项目顺利交付,并为该平台持续向全球代理机构提供高质量服务奠定了基础。
该内部项目采用 Java 开发,用于监控集群中各节点的存活状态。系统检测心跳命令的返回结果,并在节点停止响应心跳信号时通过邮件通知运维人员。 作为主开发负责人,与 5 人开发团队紧密协作推进项目开发,工作涵盖设计、实现、代码审查、测试以及环境发布等各个开发阶段。 相关技术领导与专业经验保障了项目按时完成并满足全部需求。最终交付的系统提升了运维流程的效率与有效性,使集群健康与可靠性更易保障。
担任团队负责人期间,既承担人员管理职责,也为驻场团队成员提供技术指导与培养,尤其为北京 30 名、上海 10 名同事提供指导与支持,团队工作聚焦于客户应用的测试。 凭借团队的专业能力与敬业精神,每次发布实现了 每千字节 1.79 个缺陷 的检出率,为所负责测试的应用质量与可靠性提供了有力保障。 任内持续支持并赋能团队成员,帮助其提升技能、实现职业目标;团队共同取得了出色成果,为组织的成功做出了重要贡献。
担任运维工程师期间,负责为客户提供关键的生产支持,确保系统与应用始终稳定、顺畅运行;同时协助研发团队即时排查复杂的数据问题,并凭借数据库集成与管理方面的经验,为各类挑战提供有效解决方案。 核心成果之一是将 Oracle 9i 与 MSSQL 2005 数据库整体集成,简化运维流程,使公司系统能够以更高效率运转。相关实践为组织整体成功及客户高质量服务提供了有力支撑。
担任现场技术支持专家期间,负责维护一家保险公司的业务 OA 系统,主要工作包括:使用 JavaScript 排查并修复前端故障;为服务台(helpdesk)部署新的服务器站点;以及统筹会议及其他活动的硬件网络搭建。
加载中…