学术发表:Humanities and Social Sciences Communications (Nature Portfolio, 2025)
开源仓库:https://github.com/UKGANG/tobit
本项目展示了一个完整的科学探索生命周期——从提出数理统计模型,到在 Nature 旗下子刊发表学术论文,再到向开源社区贡献工业级 Python 计算包。该研究由 美国联邦研究诚信办公室(Office of Research Integrity,项目资助编号:ORIIR190049 与 ORIIR180041) 资据,专门用于建模和预测科学文献中分享的数字资源(如数据库、代码仓库、在线工具等)的失效生命周期。
优化数学建模与算法求解
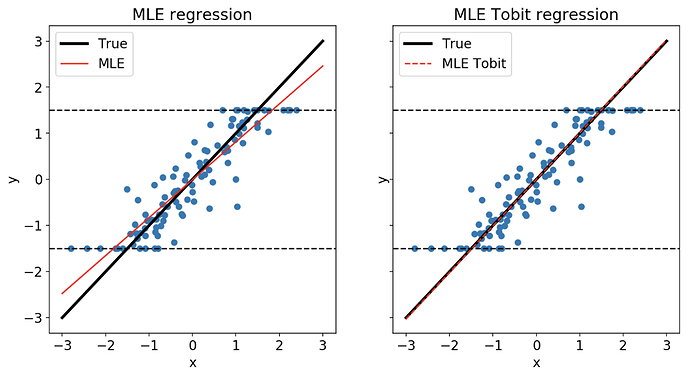
由于科学文献中共享资源的真实生存时间在统计学上存在明显的截断特征(在右侧受限于观测窗口的截止点,在左侧受限于论文刚发表即失效的初始化失败),普通的线性回归或 MLOps 模型无法有效建模。我们为此设计并实现了一个带 Elastic Net 正则化惩罚项的 Tobit 截断回归模型。
1. 潜在变量公式表达
假定底层未截断的资源寿命 $y_i^*$ 服从:
$$y_i^* = x_i \beta + \epsilon_i, \quad \epsilon_i \sim \mathcal{N}(0, \sigma^2)$$而我们实际观测到的寿命 $y_i$ 则服从如下截断约束:
$$y_i = \begin{cases} y_L & \text{if } y_i^* \le y_L \\ y_i^* & \text{if } y_L < y_i^* < y_R \\ y_R & \text{if } y_i^* \ge y_R \end{cases}$$截断分布机制: 当潜在分布超越观测区间边界 $[y_L, y_R]$ 时,无法观测到确切值,从而在边界上限 $y_R$ 和下限 $y_L$ 处产生概率密度的脉冲式累积。
2. 最大后验概率 (MAP) 估计
为了在高维学术特征(URL 校验状态、出版商元数据、作者引用指标等)下防止模型过拟合,我们使用了带 Elastic Net 惩罚项(L1 + L2 正则)的极大似然函数,这等价于在双 Laplace 和 Gaussian 先验下求解 MAP 目标函数:
$$\begin{aligned} \mathcal{L}_{\text{MAP}}(\beta, \sigma) &= -\sum_{i \in \text{Left}} \ln \Phi\left(\frac{y_L - x_i \beta}{\sigma}\right) \\ &\quad - \sum_{i \in \text{Mid}} \left[ \ln \phi\left(\frac{y_i - x_i \beta}{\sigma}\right) - \ln \sigma \right] \\ &\quad - \sum_{i \in \text{Right}} \ln \Phi\left(\frac{x_i \beta - y_R}{\sigma}\right) \\ &\quad + \lambda \left( \alpha \|\beta\|_1 + (1-\alpha) \frac{1}{2} \|\beta\|_2^2 \right) \end{aligned}$$其中 $\Phi$ 和 $\phi$ 分别为标准正态分布的累积分布函数(CDF)与概率密度函数(PDF),$\beta$ 代表回归系数向量。
3. 解析梯度加速 (Jacobian Analytical Gradients)
常规的优化算法依赖于数值差分梯度,在千万级样本下极其低效且易陷入数值不稳定。我们自主推导并实现了损失函数的精确解析梯度(_tobit_neg_log_likelihood_der),利用 逆米尔斯比率 (Inverse Mills Ratio) $\lambda(z_i) = \frac{\phi(z_i)}{\Phi(z_i)}$ 分别处理三类观测:
- 对于左截断点:$\frac{\partial \mathcal{L}}{\partial \beta} = \frac{x_i}{\sigma} \lambda\left(\frac{y_L - x_i \beta}{\sigma}\right)$
- 对于右截断点:$\frac{\partial \mathcal{L}}{\partial \beta} = -\frac{x_i}{\sigma} \lambda\left(\frac{x_i \beta - y_R}{\sigma}\right)$
- 对于未截断区间:采用标准正态密度的闭式梯度项
- 该解析梯度加速使得优化器如
L-BFGS-B能够在极少的迭代步数内收敛,确保了对海量数据的处理效率。
工业级开源计算包:Tobit-EN
为了让研究在工业界具有可复现性,将其封装并发布至 PyPI。
- scikit-learn 标准兼容:
TobitRegressor类全面继承自 scikit-learn 的BaseEstimator和RegressorMixin,无需任何胶水代码即可直接放入主流网格搜索(GridSearchCV)或机器学习流水线。 - 自举评估 (Bootstrapping):提供了内置的自举重采样模块,用以在强共线性数据环境下准确提取出排序稳定的核心特征贡献度。